
|
Руслан Фатхутдинов, руководитель отдела поискового продвижения в агентстве Реаспект. Сертифицирован в Google Analytics, Яндекс.Метрике, Sape. Автор Telegram канала «Идея украдена» |
В обсуждении с коллегами из других компаний был поднят вопрос, о том, как удобно хранить данные по оптимизации сайта (семантическое ядро, мета-теги, данные по ТЗ и их внедрению и т.п.). Я предложил свое решение этой задачи, которое мне кажется наиболее удобным для работы и восприятия.
Я называю это решение “Сводная таблица оптимизации сайта” — это хабовая таблица, агрегирующая в себе наиболее важные данные, касающиеся оптимизации сайта и помогающая контролировать его продвижение.
О том, какие данные содержаться в данной таблице я хочу рассказать в данной статье.
Сразу оговорюсь, что мы работаем в облаке google drive и его приложениях. Этому есть несколько причин:
-
С проектом работает несколько специалистов (опимизатор, проект-менеджер, копирайтеры и т.д.). Работать в облаке значительно быстрее, чем перекидываться копиями документов по почте.
-
Иногда данные могут потребоваться, когда специалист физически находится не у рабочего компьютера, а телефон или планшет всегда под рукой.
-
Возможность легкой миграции данных между документами.
У нас есть стандартизированная структура, как хранить данные по проектам в google drive, чтобы можно было взять нужную информацию, не отвлекая других от работы.
Структура выглядит следующим образом:
-
У каждого специалиста есть папка “Проекты”
-
Для каждого проекта заводится своя папка с соответствующим названиям
-
Внутри папки проекта есть несколько стандартных подпапок, и уникальные папки под потребности проекта.
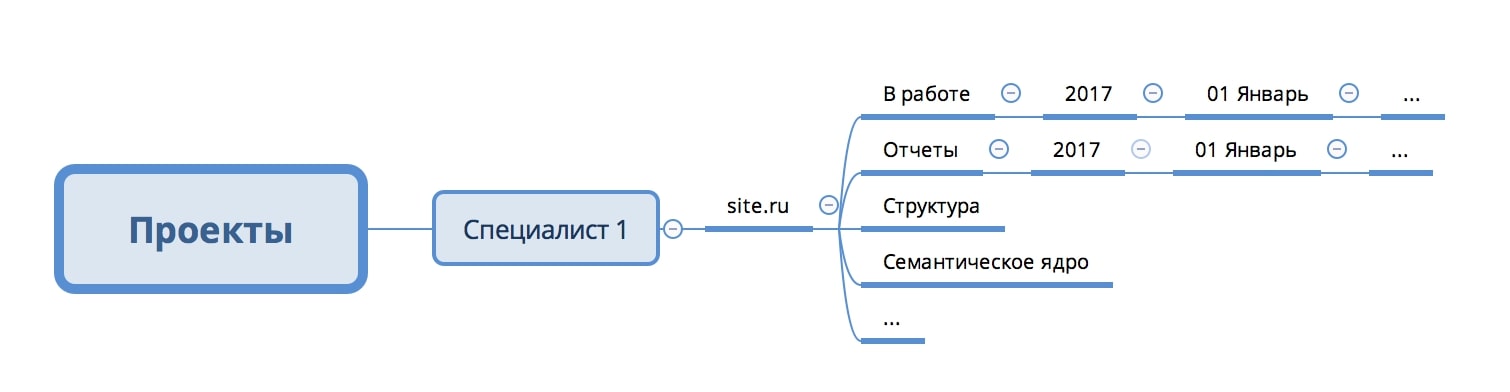
Рис. 1 Структура папки проекта
Мы составляем сводную таблицу в начале работы над проектом, и дополняем ее на протяжении всей работы.
Стандартные столбцы, используемые в таблице:
-
URL — адреса страниц. Данные из столбца также могут использовать в качестве якоря для функций (ВПР, СУММЕСЛИ и т.п.);
-
Структура — место страницы в структуре сайта. Аналог классических хлебных крошек;
-
Тип — к какому типу относится страница. Особенно актуально для интернет-магазинов, в которых мы выделяем такие типы, как: “Каталог”, “Тег”, “Фильтр”, “Карточка”, “Информационная” и “Вспомогательная”;
-
H1 — h1 заголовок страницы;
-
Title — title страницы;
-
H2 — список заголовков h2 для страницы;
-
Текст — пометка о статусе текста на странице в формате “Есть”, “Нет”, “ТЗ”;
-
Месяц — когда в последний раз производились (в) работы или планируются производиться (п) работы над страницей, в формате “ММ.ГГГГ”
-
Семантическое ядро — в столбце выкладывается ссылка на на файл, в котором содержится семантическое ядро для соответствующего раздела.
Кроме описанных столбцов, в зависимости от задачи, таблица дополняется и другими данными, например:
-
Запрос — основной запрос для страницы;
-
Группа столбцов по частотностям запроса — в зависимости от сайта, могут содержаться как классические частотности (Ч, “Ч”, “!Ч”, “[!Ч]”), так и, с наложением коэффициента по поисковым системам;
-
Группа столбцов сезонности за последние 12-24 месяца;
-
И другие.
С шаблоном таблицы вы можете ознакомиться по ссылке.
Заполнить таблицу первичными данными можно и руками.
Но данный способ не всегда оптимальный, поэтому мы в своей работе используем Screaming Frog SEO Spider.
Пример работы я буду показывать основываясь на взаимодействии с данным инструментом.
Перед началом парсинга отключаем все бесполезные функции, которые нам не понадобятся (Configuration — Spider):
-
Проверку изображений;
-
Проверку ресурсов (js, css и swf);
-
Проверку внешних исходящих ссылок.
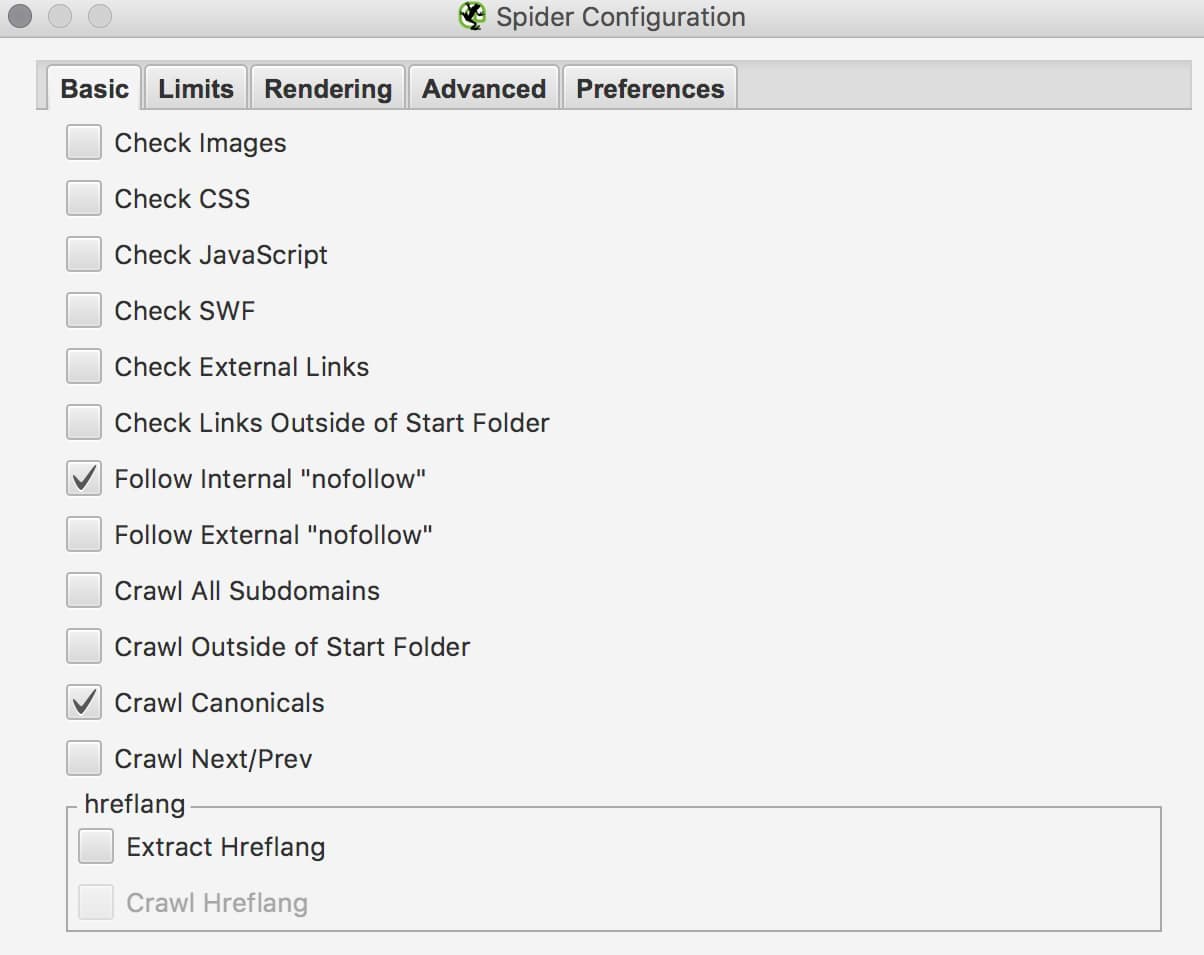
Рис. 2 Настройка Screaming Frog
Далее копируем Xpath корневого блока хлебных крошек на сайте, если они там есть.
Для этого:
-
Открываем внутреннюю страницу, на которой есть хлебные крошки в google chrome
-
Открываем консоль (Ctrl + Shift + i)
-
Выделяем инспектором корневой блок хлебных крошек
-
В контекстном меню выбираем Copy XPath.
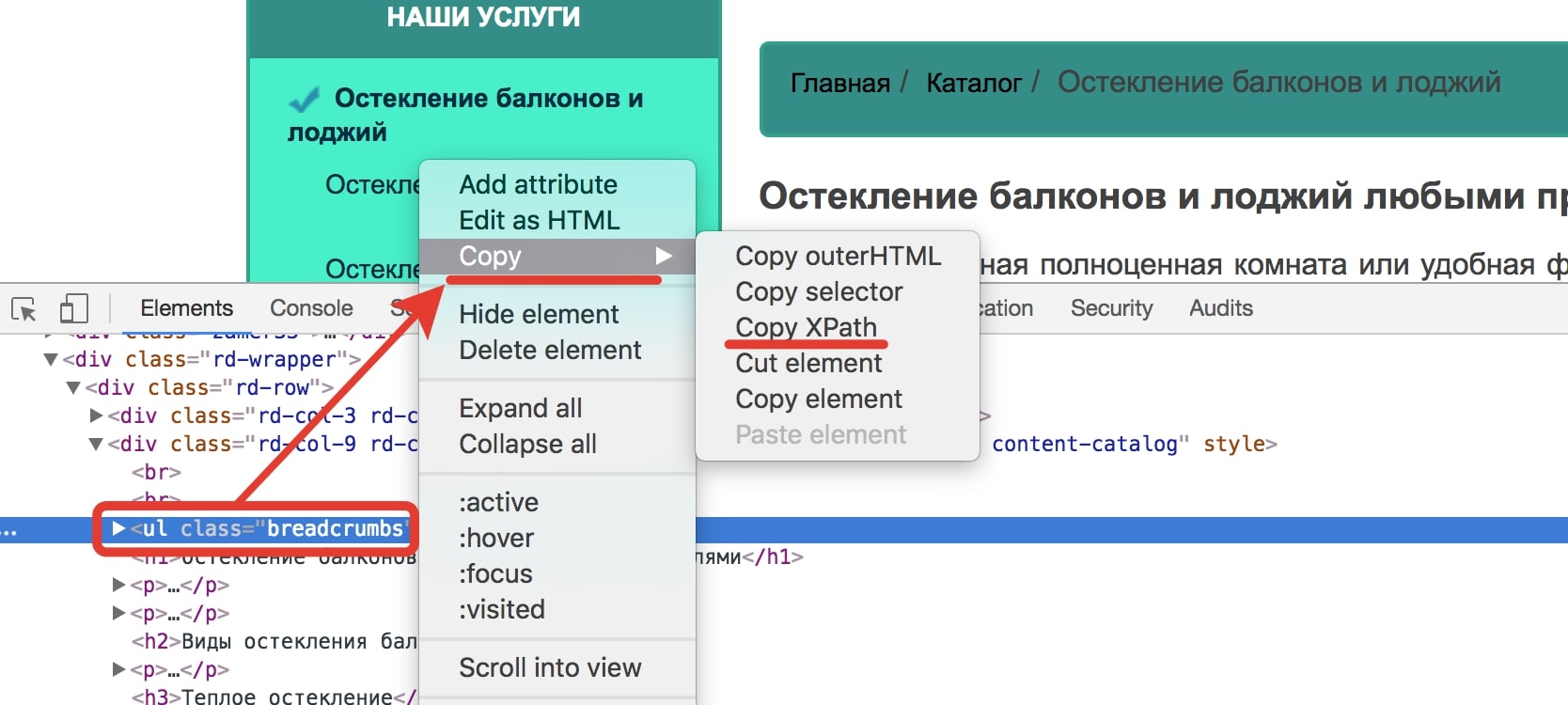
Рис. 3 Копирование XPath
-
В Screaming Frog переходим в Configuration — Custom — Extraction
-
В открывшемся окне:
-
Выбираем “XPath”
-
Вставляем скопированный путь
-
“Extract Text”.
-

Рис. 4 Extraction в SCSS
И парсим сайт.
После того как сайт спарсится выгружаем отчеты:
-
Информация по html (Internal — HTML);
-
Хлебные крошки (Custom — Exctraction);
И переносим данные отчета в сводную таблицу.
Чтобы не перепутать данные и колонки не “поехали”, можно воспользоваться функцией ВПР.
Нас интересуют:
-
Url
-
H1
-
Title
-
Хлебные крошки
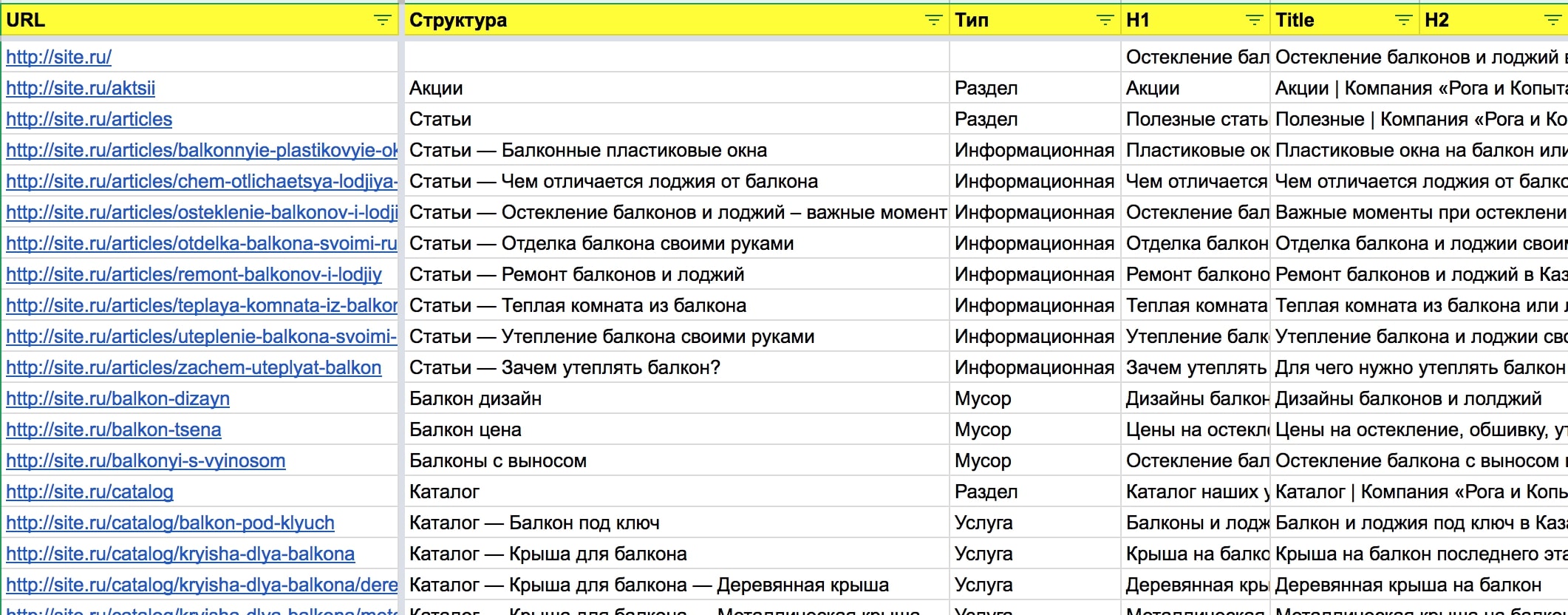
Рис. 5 Заполненная первичными данными таблицы
Пример таблицы заполненной первичными данными по ссылке, на вкладке “Пример”.
Алгоритм дальнейшей работы полностью зависит от типа проекта, цели продвижения и выбранной стратегии.
С внедрением данного инструмента в свою работы мы решили многие задачи, которые остро стоят перед каждым специалистом (все мета-теги в одном месте, контроль выполнения задач и т.п.).
Надеюсь, вам подобная сводная таблица тоже будет полезна.
Если у вас есть вопросы, пишите мне на e-mail rus@reaspekt.ru, обсудим вместе.